Databricks - Data Engineering
Easily ingest and transform batch and streaming data on the Databricks Data Intelligence Platform. Orchestrate reliable production workflows while Databricks automatically manages your infrastructure at scale and provides you with unified governance. Accelerate innovation by increasing your team’s productivity with a built-in, AI-powered intelligence engine that understands your data and your pipelines
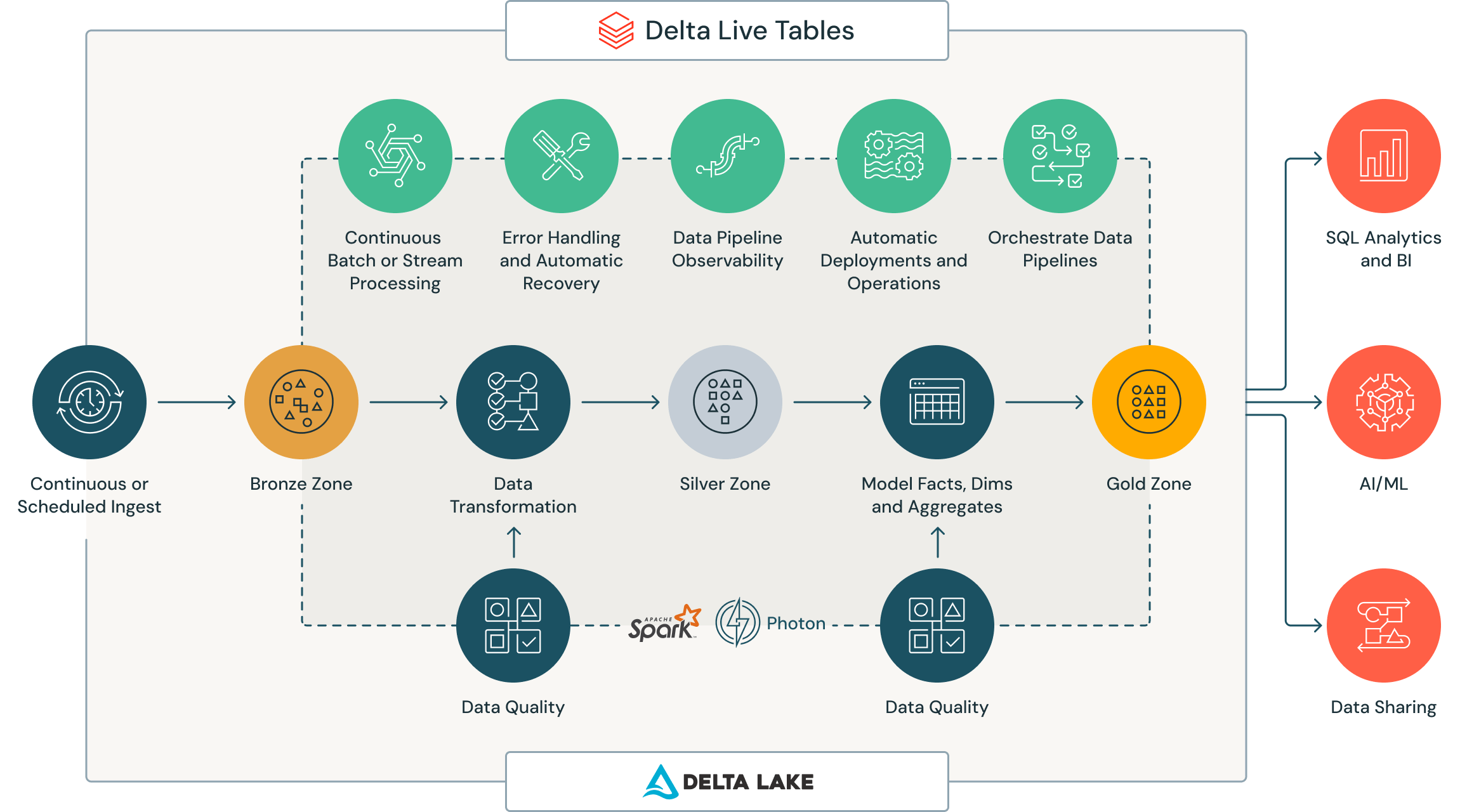
Trustworthy data from reliable pipelines
Data needs to be ingested and transformed so it’s ready for analytics and AI. Databricks provides powerful data pipelining capabilities for data engineers, data scientists and analysts with Delta Live Tables. DLT is the first framework that uses a simple declarative approach to build data pipelines on batch or streaming data while automating operational complexities such as infrastructure management, task orchestration, error handling and recovery, and performance optimization. With DLT, engineers can also treat their data as code and apply software engineering best practices like testing, monitoring and documentation to deploy reliable pipelines at scale.
Unified workflow orchestration
Databricks Workflows offers a simple, reliable orchestration solution for data and AI on the Data Intelligence Platform. Databricks Workflows lets you define multistep workflows to implement ETL pipelines, ML training workflows and more. It offers enhanced control flow capabilities and supports different task types and triggering options. As the platform-native orchestrator, Databricks Workflows also provides advanced observability to monitor and visualize workflow execution along with alerting capabilities for when issues arise. Serverless compute options allow you to leverage smart scaling and efficient task execution.


Powered by data intelligence
DatabricksIQ is the Data Intelligence Engine that brings AI into every part of the Data Intelligence Platform to boost data engineers’ productivity through tools such as Databricks Assistant. Utilizing generative AI and a comprehensive understanding of your Databricks environment, Databricks Assistant can generate or explain SQL or Python code, detect issues, and suggest fixes. DatabricksIQ also understands your pipelines and can optimize them using intelligent orchestration and flow management, providing you with serverless compute.
Next-generation data streaming engine
Apache Spark™ Structured Streaming is the most popular open source streaming engine in the world. It is widely adopted across organizations in open source and is the core technology that powers streaming data pipelines on Databricks, the best place to run Spark workloads. Spark Structured Streaming provides a single, unified API for batch and stream processing, making it easy to implement streaming data workloads without changing code or learning new skills. Easily switch between continuous and triggered processing to optimize for latency or cost.


State-of-the-art data governance, reliability and performance
Data engineering on Databricks means you benefit from the foundational components of the Data Intelligence Platform — Unity Catalog and Delta Lake. Your raw data is optimized with Delta Lake, an open source storage format providing reliability through ACID transactions, and scalable metadata handling with lightning-fast performance. This combines with Unity Catalog, which gives you fine-grained governance for all your data and AI assets, simplifying how you govern, with one consistent model to discover, access and share data across clouds. Unity Catalog also provides native support for Delta Sharing, the industry’s first open protocol for simple and secure data sharing with other organizations.